[Special Issue] 빅데이터, 세상을 바라보는 또 다른 시각
2013.06.05 11:29 광고계동향,
조회수:12009

행정안전부에 따르면 2013년 3월 우리나라 인구수는 총 51,003,843명이다. 얼마나 많은 숫자일까? 누군가를 만나서 통성명을 하고 인사를 나눌 때 소요되는 시간을 30초라고 한다면 대한민국 인구 5,100만 명을 다 만나기 위해 필요한 시간은 얼마나 될까? 하루 8시간 잠자는 시간만 제외하고 누군가를 만나서 인사를 나눈다고 했을 때 우리나라 사람을 다 만나서 인사를 나누기 위해서는 무려 73년이라는 시간이 소요된다는 계산이 나온다. 전세계 70억 인구와 인사를 나누기 위해서는 9,989년. 그러고 보면 평생에 걸쳐 한번도 마주치지 못할 대다수의 사람들 속에서 우리가 일상에 마주치는 인연들은 너무나 소중한 인연이 아닐까 싶다. 우리나라에서만 이렇게 많은 사람들이 디지털기기를 사용하면서 수많은 데이터를 생성해내고 있다. 스마트폰으로 사진을 찍고 SNS를 사용하고 검색을 하고, 자동차에서는 쉴새 없이 블랙박스가 디지털 동영상을 만들어내고 있다. 이렇게 만들어지는 전세계 디지털 데이터의 양은 2020년까지 전세계 해변의 모래알의 수인 7.005×1020의 57배에 달하는 40ZB(40×1021byte)*가 될 것이라고 하니 빅데이터는 그 크기를 상상조차 하기 힘들다.
* EMC 디지털 유니버스 보고서 : 빅데이터, 더욱 길어진 디지털 그림자,
이머징 마켓의 놀라운 성장' 연구 결과 보고서
그렇다면 이렇게 무지막지한 빅데이터로 무엇을 할 수 있을까? 빅데이터는 그 동안 우리가 보지 못해서 알지 못했던 많은 것들을 보게 해주고 알게 해주고 이해하게 해주는 도구가 될 수 있다. 영화 매트릭스에서 주인공인 네오는 초인이 되어 비 오듯 흘러내리는 암호코드를 완벽히 이해하게 되는 순간 매트릭스 시스템을 완전히 지배하게 된다. 영화에서처럼 세상을 완전하게 이해하고 지배할 수는 없겠지만 빅데이터를 활용한다는 것은 세상과 사람을 이해하는데 일말의 도움을 줄 수 있다는 데 그 의미와 가치가 있다. 특히, 소비자가 무슨 생각을 하는지, 무엇을 선호하는지, 무엇을 싫어하는지, 왜 좋아하고 싫어하는지를 알고 싶어하는 마케터라면 옆에 있는 연인의 마음 속을 읽지는 못하더라도 소비자의 마음 속을 읽어낼 수 있는 빅데이터를 주목할 필요가 있다. 빅데이터는 한 사람이 아닌 여러 사람이 걸어가면서 만들어낸 길처럼 패턴과 흐름이 있기 때문이다.
마케터에게 의미를 가지는 빅데이터를 크게 나눠보면 Inside data와 Outside Data로 구분 지을 수 있다. Inside Data는 기업 내부에서 생성하고 관리하는 데이터이며 과거 고객 매출 데이터, 로그데이터, 트래픽 데이터 등 과거 CRM 차원에서 생성/관리되던 데이터이다. Outside data는 소셜미디어 데이터, 포털 검색 데이터, 외부 사이트 트래픽 데이터 등 기업 바깥에서 생성되는 소비자 데이터이다.
소위 ‘빅데이터를 한다.’라고 생각을 한다면 외부에서 빅데이터를 찾아다니기 전에 우선적으로 기업 내부에서 쌓아두고 있는 데이터에 주목할 필요가 있다.
필자는 약 10년 전, B2B e-Marketplace를 운영하는 전자상거래 회사에서 근무했었다. 당시 4개월에 걸친 40만 건의 검색 로그데이터를 오피스 프로그램인 엑세스와 엑셀을 활용하여 매출 데이터와의 교차 분석을 통해 어떤 시간대에 검색이 매출로 이어지는지, 어느 구매사가 어떤 키워드로 주로 검색을 하는지, 요일별/시간대별 검색량은 어떠한지, 검색 트래픽이 특정 시간대에 얼마나 편중되고 서버에 얼마만큼 부하를 주는지 등을 분석하여 전자 카탈로그시스템의 7가지 개선과제를 도출하였고 결과적으로 전자 카탈로그 이용률과 만족도 모두 큰 폭으로 향상시키는 데 일조했던 적이 있다. 40만 건의 데이터는 빅데이터라고 하기에는 큰 숫자가 아닐 수 있다. 하지만 호수가 넓다고 해서 낚시가 꼭 잘 되는 게 아닌 것처럼 ‘Big’데이터가 반드시 큰 효용을 가져다 주는 것은 아니라는 점을 명심해야 한다. 빅데이터는 과거에 없던 것이 새로 생겨난 것이 아니라 그 동안 간과하고 있던 데이터를 어떻게 활용할 것인지를 재조명하게 되는 촉발제로서의 의미가 더 크다고 할 수 있다. 빅데이터를 ‘Big’이 아닌 ‘효용’에 초점을 맞춰야 하는 이유이다. 그래서 마케터에게 빅데이터는 ‘큰 데이터’라고 쓰고 ‘데이터를 새롭게 조명함으로써 인사이트를 발굴하고자 하는 시도’라고 읽는 게 타당하지 않을까 싶다.
사이트 방문자의 행동 분석 - 로그 데이터 분석
사이트 방문자의 행동 분석 - 로그 데이터 분석
이렇듯 기업 내부의 데이터는 활용하기에 따라 높은 가치를 지니는 정보가 될 수 있는데 로그 데이터는 그 중에서도 가장 쉽게 접근할 수 있고 범용적으로 활용할 수 있는 데이터라고 할 수 있다. 온라인 광고의 집행 성과를 분석하고 개선하는 데에도 폭넓게 활용되는 로그 데이터는 그 외에도 방문자의 동선을 파악하고 홈페이지의 구성을 개선시키는 데에도 활용되어질 수 있다. 크레이지에그(www.crazyegg.com), 클릭테일(www.clicktale.com), 클릭덴시티(Clickdensity) 등의 사이트에서는 방문자의 페이지 내의 이동 궤적과 행동 패턴을 직관적으로 이해할 수 있는 인터페이스를 제공한다.
페이지 내에서 마우스가 이동한 궤적을 기록하거나 (Mouse Move), 마우스가 클릭된 구간을 한눈에 표시하거나 (Heatmap), 홈페이지에 방문한 고객이 방문 후 몇 초 후에 어느 메뉴를 클릭했는지, 모니터 해상도가 작은 방문자들은 페이지에서 주로 클릭한 영역은 어디인지 (Confetti 분석), 방문자를 샘플링하여 페이지 이탈까지의 마우스 이동 궤적을 녹화(Video Record)하는 등의 서비스를 제공한다.
아래 그림의 경우는 필자의 블로그에 무료 테스트를 진행한 결과이다. 페이지 내에서 어느 영역이 평균적으로 몇 초간 주목을 받았는지를 나타내는 ‘Scroll Reach’ 분석 화면이다. 만약에 상품페이지라고 가정했을 때 상품의 핵심적인 정보 혹은 할인정보가 평균 3초를 주목하는 마지막 영역에 위치해있다면 방문자가 주목할 확률이 적을 것이다. 이러한 분석을 통해 방문자가 집중적으로 주목하는 영역에 핵심 정보를 배치하는 등의 페이지 구성 최적화 작업이 이루어질 수 있다.

소비자 관심의 흔적 - 검색 데이터
Inside Data가 우리 홈페이지에 방문한 우리의 고객들을 이해한 것이라면 Outside Data는 우물 안쪽이 아닌 우물 바깥 쪽의 소비자를 이해하는 훌륭한 데이터가 된다. 검색데이터는 Outside Data 중에 가장 쉽고 편하게 접근하면서도 많은 인사이트를 얻을 수 있는 데이터이다. 검색 통계 데이터는 네이버, 다음, 구글과 같은 포털에서 제공하고 있다.
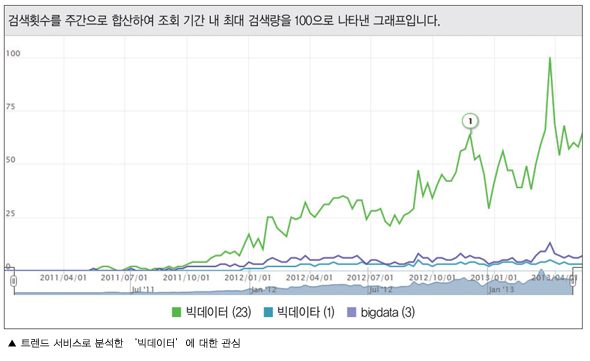
‘빅데이터’의 관심은 언제부터 형성된 것일까? 그리고 그 관심은 줄어들고 있을까? 늘어나고 있을까? 사람들은 ‘빅데이터’, ‘빅데이타’, ‘Big Data’ 를 어떻게 언급할까? 네이버 트렌드 서비스로 분석을 해보면 빅데이터는 2011년 5월 23일부터 조금씩 검색되기 시작했고 빅데이터(82%), 빅데이타(6%), bigdata(12%)로 검색한다는 것과 빅데이터는 현재 관심이 줄지 않고 지속적인 증가 추세를 보이고 있다는 것을 알 수 있다. 아직 빅데이터는 살아 있다는 것을 확인할 수 있는 대목이다.
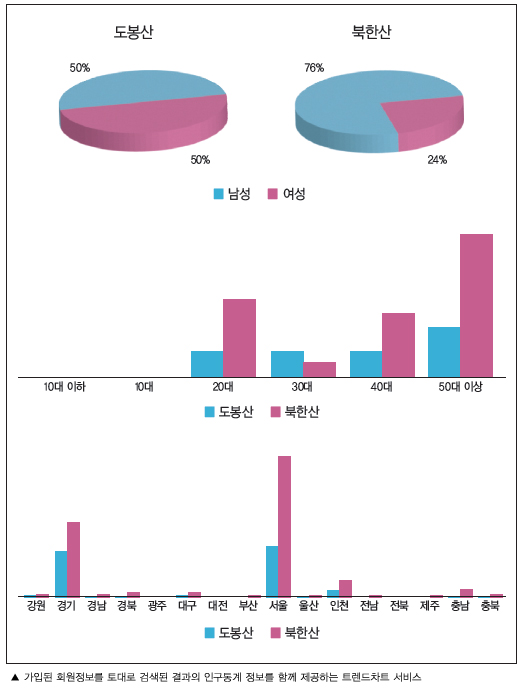
다음의 트렌드차트 서비스는 다음의 가입된 회원정보를 토대로 검색된 결과의 인구통계 정보를 함께 제공한다. 다음에서 ‘도봉산 vs 북한산’을 검색해보면 도봉산의 여성 검색 비중이 50%로 북한산(24%)보다 26%나 높은 것을 알 수 있다. 또한, 50대가 특별히 많이 찾는 북한산에 비해 도봉산은 전 연령대에 고르게 분포되어 있으며 의외로 인천 지역에서 북한산을 많이 찾는 것을 알 수 있다.
네이버 검색 트렌드, 다음 트렌드차트 이외에도 포털의 광고주 센터에서 제공해주는 다양한 통계 데이터는 소비자들의 관심사의 변화 추이와 다양한 정보를 알 수 있게 해준다.
검색 빅데이터의 활용 사례로 단연 꼽히는 것은 구글의 독감 트렌드 서비스(http://www.google.org/flutrends)를 들 수 있다. 독감이 걸린 사람은 구글에서 독감과 관련한 키워드로 검색을 하게 되고 이렇게 검색된 데이터에서 패턴을 읽어 전 세계 여러 국가 및 지역의 독감 유행 수준을 파악하여 경보해주는 서비스이다. 미국의 질병 통제 센터보다 2주 정도 빠르게 독감 유행을 예측하여 네이쳐(Nature) 지에 게재되기도 하면서 빅데이터의 대표적인 성공 사례로 꼽힌다. 하지만 최근 1월의 미국 전체 인구의 11%가 독감 환자라고 예측한 구글의 공식이 잘못되었다고 네이쳐지가 발표하고 미국 질병 통제센터에서 구글의 추정치의 절반(6%)만이 독감환자였다는 사실을 공개하면서 구글의 독감 트렌드 서비스가 머쓱해지는 상황이 발생하였다. 왜냐하면 올해와 같은 경우 특히 심한 독감이 발생하였기 때문에 설사 독감이 걸리지 않은 사람이더라도 독감을 검색할 확률이 높아졌기 때문일 수도 있고 소셜미디어에서 독감에 대한 이슈가 확산되면서 독감의 검색량이 급증했을 수도 있다. 이렇듯 상황적인 맥락을 이해하지 않고 데이터에만 의존한 빅데이터 분석은 현실을 호도하는 결과를 낳을 수 있다. 데이터가 거짓말을 하지는 않지만 의도치 않은 거짓 해석이 될 수 있다는 것이다.
맥락의 이해는 검색 데이터 외에 소셜미디어와 같은 소비자들의 자연발생적인 문서 내에서 행간에 담겨진 의미 분석을 통해 보완될 수 있다. 소비자들의 다양한 생각과 정황, 감정 정보가 담겨진 소셜 빅데이터는 트렌드 발굴 및 트렌드의 촉발 요인 분석 등이 가능하다. 소셜 빅데이터 분석을 통해 소비자의 트렌드를 어떻게 읽고 해석할 수 있는지에 대해서는 다음 호에서 사례와 함께 이야기하기로 하겠다.
빅데이터는 거스를 수 없는 대세일까? 한 때의 유행일까? 우리는 빅데이터라는 큰 파도 속에서 소위 ‘빅데이터를 해야 한다.’는 강박관념을 가지고 있는 것은 아닌가 싶다. 그럴수록 빅데이터의 초점이 ‘효용’이 아닌 ‘Big’에 맞추어질 수 있다는 점을 경계해야 한다. 빅데이터가 원하는 것을 뚝딱 꺼내오는 요술램프라고 여기고 빅데이터가 만들어낼 미래에 대해 너무나도 성급하게 새로운 세상이 펼쳐질 것처럼 예단하는 것 또한 경계해야 한다. 분명한 것은 ‘Big’이든 ‘Small’이든 소비자들이 은연 중에 남기게 되는 흔적 데이터에서 의미를 찾고 가치를 발견하려는 시도가 확산된다는 점은 사람을 이해하고 보다 나은 세상을 만들어가는 디딤돌이 될 것이라는 점이다.
[글 | 신도용 다음소프트 더마이닝컴퍼니 전략기획팀장]